
Kafka是大型架构核心,下面我详解Kafka高吞吐技术@mikechen
顺序写入与零拷贝机制
Kafka 的消息写入是顺序写入磁盘,而非随机写。
磁盘顺序写的速度远超随机写,即使机械硬盘也能接近内存级性能。

Segment 文件顺序写入:每个 Partition 对应一组顺序的日志文件。
OS Page Cache 利用:Kafka 不自己管理缓存,而依赖操作系统的页缓存(Page Cache)进行文件读写缓冲。
零拷贝 (Zero Copy):通过 sendfile() 系统调用直接在内核中完成数据传输,无需反复拷贝到用户态。
减少 I/O 开销、降低 CPU 消耗、提升写入与读取速度。
分区化与并行处理
Kafka 的核心结构是 Topic → Partition → Replica。
分区机制带来的好处:
每个 Partition 可以独立存储、独立消费。
多个 Partition 可分布在不同 Broker 上,实现并行读写。
Consumer Group 内的多个消费者可并行消费不同分区。
示例:
一个 Topic 拆分为 10 个 Partition,10 个消费者同时消费,理论上吞吐可提升 10 倍。
支持水平扩展。
充分利用多核与多机器并发能力。
批量传输与压缩
Kafka 在网络层采用 批量发送 和 压缩机制 来显著提升吞吐。

主要手段:
Producer 端批量发送:通过 batch.size 和 linger.ms 参数,将多条消息合并成一批发送。
Broker 端批量存储:消息按批次写入日志文件,减少磁盘 I/O。
压缩算法支持:支持 gzip、snappy、lz4、zstd 等压缩方式,大幅降低网络带宽占用。
网络传输减少 70% 以上带宽占用。
每批次写入日志一次,显著提升写入吞吐。
异步复制与可配置的持久化策略
Kafka 基于 NIO(非阻塞 I/O) 实现异步通信,减少线程上下文切换。
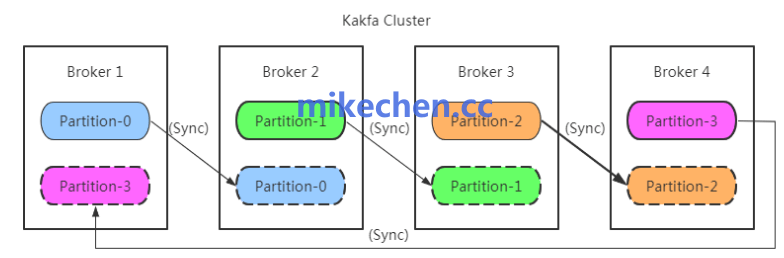
优化点包括:
基于 Selector 的 Reactor 模型:单线程可处理成千连接。
零拷贝 sendfile():数据在磁盘与网卡之间直接传输,无需用户态参与。
批量响应机制:Broker 可同时返回多批确认信息,减少网络往返。
高并发下 CPU 利用率低。
延迟降低,整体吞吐显著提升。