
数据库是大型架构核心,下面我详解MySQL千万QPS方案@mikechen
读写分离
核心思想,写:集中在主库,读:分摊到多个从库。
通过主从复制或多主复制,将读请求导向只读副本、将写请求集中到主节点,显著降低主库压力。
结合延迟可接受的场景,可部署大量只读副本以扩展读QPS。

为什么这是第一层放大器?
现实业务中:
读请求占 80%~95%;
写请求占比极低;
架构效果:
1 个主库写
+ N 个从库读
存储引擎优化

MySQL性能的底层决定因素来自存储引擎(如InnoDB)的设计与索引策略。
关键技术包括:
索引设计与覆盖索引,减少回表和IO操作。
行格式、压缩与页大小优化,降低磁盘与内存占用。
并发控制(乐观/悲观锁、MVCC)与减少锁争用。
IO调度与预读、缓冲池(Buffer Pool)调优,提升命中率与并发吞吐。
使用非阻塞复制、GTID与并发应用日志(binlog)优化写入通道。
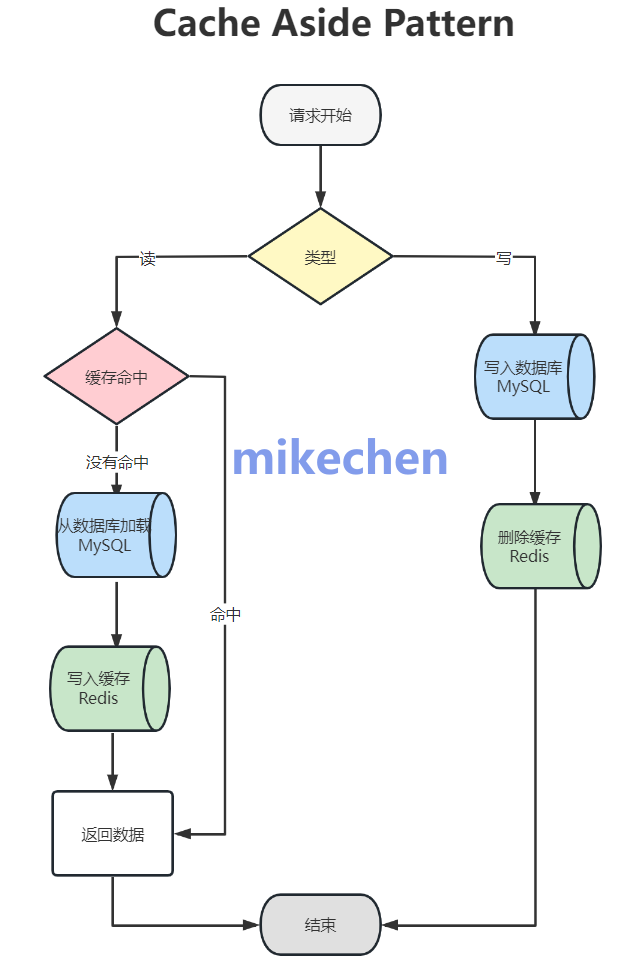
引入缓存层
在应用层或中间件层,引入分布式缓存(如Redis、Memcached)。
能将热点数据请求截流,大幅减少对MySQL的直接访问。
缓存设计包括显式缓存、二级缓存、热点预热、负载均衡与缓存穿透/雪崩防护。
配合合理的失效与更新策略(如异步更新、延迟双删)可在性能与一致性之间取得平衡。
数据库拆分

这是达成千万 QPS 的“入场券”,既然单台机器有上限,那就把数据分散到 100 台甚至 1000 台机器上。
核心逻辑: 通过 Hash 或 Range 算法,将海量数据均匀分布在多个物理节点。
效果: 100 个节点,每个节点承担 10 万 QPS,理论上就能支撑 1000 万 QPS。
挑战: 解决了容量问题,但带来了分布式事务、跨库 Join 等复杂难题。
通常需要配合 ShardingSphere 或 Vitess 等中间件。