
高并发是大型架构核心,下面我详解Kafka亿级流量@mikechen
磁盘顺序读写 (Sequential I/O)
首先,磁盘顺序读写是 Kafka 性能的基础。
消息以追加(append-only)方式写入日志,读取亦多为顺序扫描。
这使得磁盘的顺序 I/O 得以充分利用,减少寻址与随机读写开销,从而提升吞吐能力。
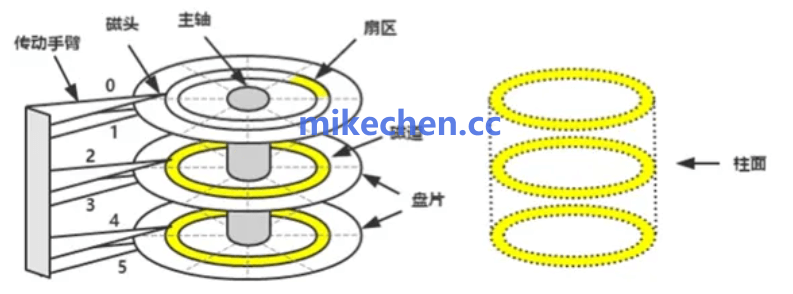
机械硬盘随机读写:磁头来回寻道,IOPS 只有几百。
顺序读写:磁头不动,吞吐可达 200MB/s+
单 Partition 顺序写 TPS 可轻松破 20 万,多 Partition 并行累加到单机百万 TPS。
零拷贝 (Zero-Copy)
其次,零拷贝(Zero-Copy)机制进一步降低了数据在内核与用户空间间的复制成本。
Kafka 使用如 sendfile 等系统,调用直接在内核态完成从页缓存到网络套接字的数据传输。
避免冗余内存复制,减少 CPU 占用并提高网络传输效率,尤其在大批量数据传输时效果显著。

传统读文件→用户缓冲→内核缓冲→socket 的多次拷贝,每次都要 CPU 参与。
Kafka 用 sendfile() 系统调用直接从 Page Cache 发到网卡,省去 2-3 次拷贝。
页缓存 (Page Cache)
页缓存(Page Cache)作为操作系统层面的缓存机制,与 Kafka 的顺序访问模式高度契合。
Kafka 不自己管缓存,直接用 OS Page Cache:
写:数据直接落 Page Cache,异步刷盘(99% 场景读写都在内存)
读:Consumer 先从 Page Cache 命中,命中率常年 95%+,延迟近内存速度。
写入操作首先落到页缓存,随后由内核异步刷盘。
读取操作若命中页缓存则无需访问磁盘,极大降低 I/O 延迟。
得益于顺序写入与热数据局部性,页缓存命中率高。
从而缓解后端存储压力,提升整体服务稳定性。
分片并行 (Partitioning)
最后,分片并行(Partitioning)为 Kafka 提供了天然的水平扩展能力。

总吞吐 = Broker 数 × 单 Broker 吞吐 × Partition 因子 举例:20 Broker,每台 50 万 msg/s,副本数=3 读 QPS:20 × 50 万 × 3 = 3000 万 QPS(副本分担读) 写 QPS:20 × 50 万 = 1000 万 QPS 日总量:1000 万 msg/s × 86400 = 86.4 万亿条/天
将主题拆分为多个分区后,生产者与消费者可并发读写不同分区。
Broker 可在多核与多磁盘环境中并行处理请求,负载得以均匀分散。
分区还方便副本机制与故障隔离,确保高可用性与数据一致性。