
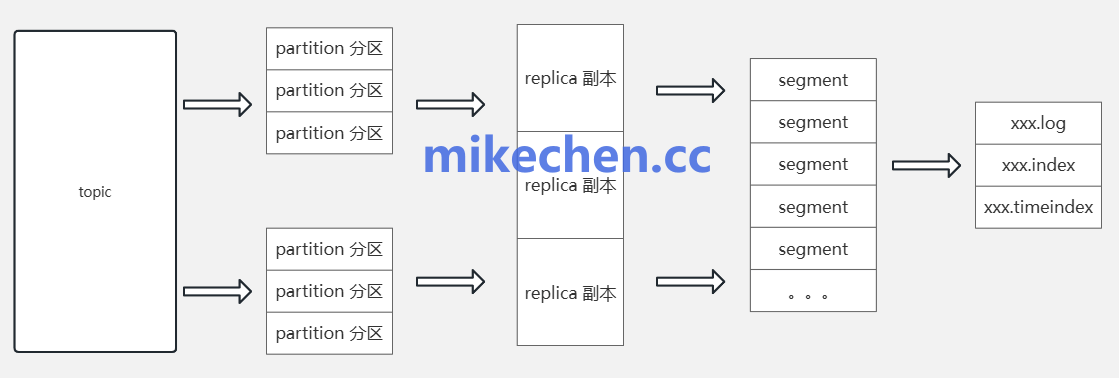
多副本机制
为了避免单点故障与数据丢失,Kafka 通过副本机制将每个分区的数据复制到多个 Broker。

必须合理设置副本因子(replication.factor),通常不低于3。
核心在于 ISR 集合的维护:仅将处于同步状态的副本视为可靠可用副本。
在写入路径上,应结合 acks 配置(acks=all)与 min.insync.replicas 参数。
确保在主副本故障时仍有足够同步副本继续接受写入,从而实现强一致性与可用性之间的平衡。
分区策略
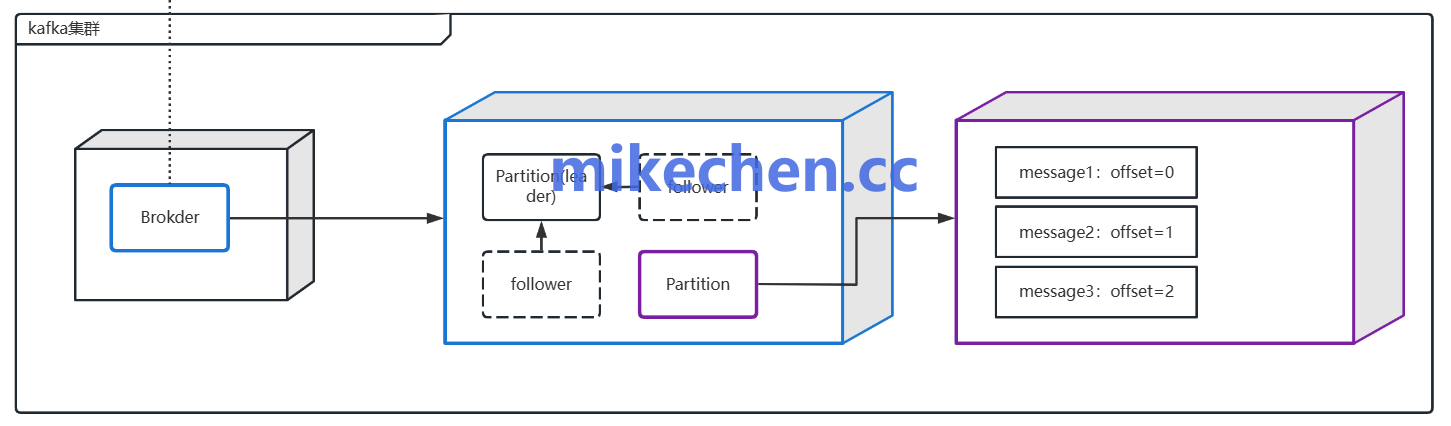
分区是 Kafka ,实现并行与扩展性的基本单位。
合理的分区数能够分散负载、提升并发消费能力,但过多分区会增加元数据与协调开销。
生产者端,应根据业务键合理分配分区以保持消息有序性。
Broker 集群层面,应使用动态分区重平衡(如 Cruise Control 等工具)。
在 Broker 宕机或扩容时均衡分布分区与副本,避免热点与资源不均,保障集群长期稳定运行。
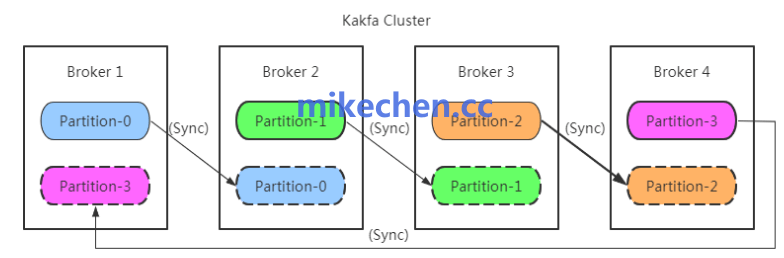
故障恢复机制
Kafka 集群,依赖单一 Controller 负责元数据管理与分区领导者选举。
为降低 Controller 成本,应设计稳定的选举流程与快速故障切换策略,缩短不可用窗口。
使用 ZooKeeper(或 KRaft 在新版本中替代)保证元数据一致性,并在异常发生时触发自动领导者选举、ISR 更新与副本同步。
同时,应配置合理的 leader.imbalance.threshold、unclean.leader.election.enable 等参数。
权衡可用性与数据安全,避免在关键时刻出现脏读或数据丢失。
运维、监控与容灾策略
高可用不仅是架构设计,还依赖完善的运维与监控体系。
需要覆盖的关键指标包括:Broker 可用性、分区领导分布。
ISR 大小、滞后副本(replica lag)、请求延时与磁盘利用率。
基于告警策略实现主动干预,定期演练故障恢复与滚动升级流程以验证可用性。
跨数据中心部署(MirrorMaker 或跨集群复制),可以实现灾难恢复与地域冗余,但需处理跨域副本一致性与带宽成本问题。