
Kafka是大型架构核心,下面我详解Kafka堆积问题@mikechen
增强消费能力
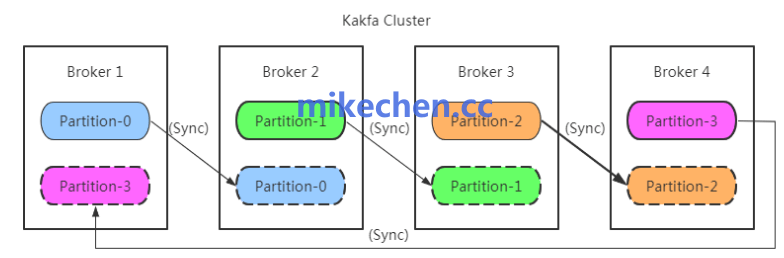
当堆积源于消费者处理能力不足,应优先增强消费侧资源与并行度。
增加消费者实例或消费组并发数,充分利用分区并行性;
确保分区数与消费者实例匹配,以避免热点分区。
提升消费者处理性能:优化消息处理逻辑、使用批量消费.
异步IO以及连接池等技术,减少每条消息的处理延迟。
合理调整消费者配置,如增加fetch.size、fetch.max.wait.ms、max.poll.records等参数,以提高吞吐效率。
优化生产端与消息体积
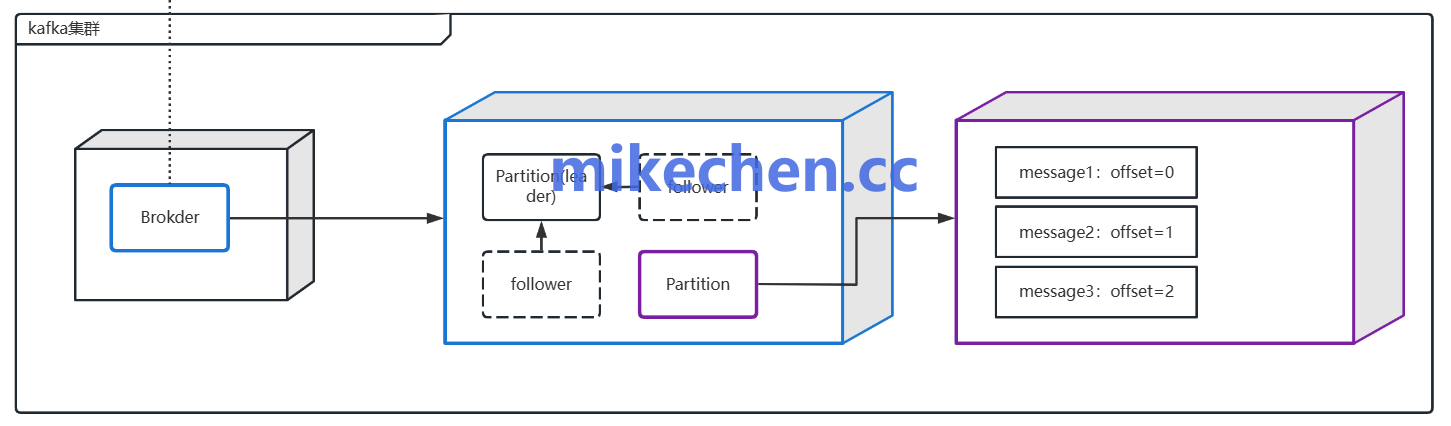
生产端不当也会导致堆积,应从源头控制入队速率与消息大小。
限制消息大小并压缩消息(如使用GZIP或Snappy),减小网络与磁盘压力。
应用端实行流量控制:在高峰期使用速率限制、背压或批量发送策略,避免瞬时流量冲击。
合理分区键策略,避免单个分区成为吞吐瓶颈,均衡写入负载。
流控与背压设计
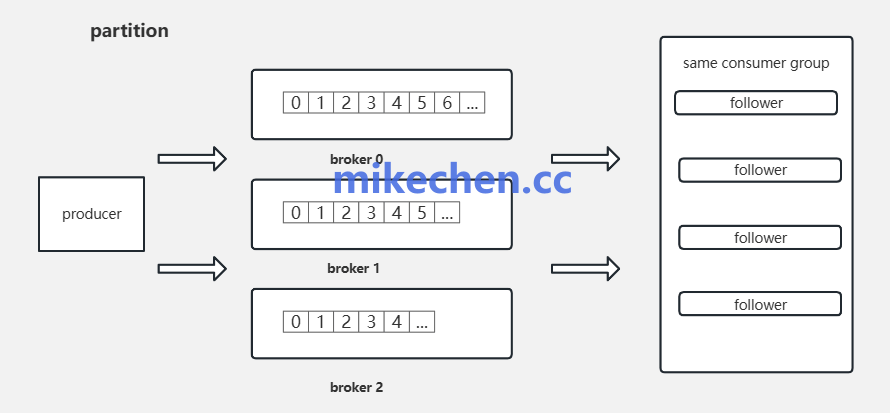
集群层面的配置直接影响写入与消费性能,应结合监控调整。
扩容Broker与磁盘IO:增加Broker节点。
使用更快的磁盘(SSD)与网络带宽,提升整体吞吐。
调整副本与ISR参数:在允许的容错范围内减少副本同步开销。
或调整min.insync.replicas,以平衡可靠性与性能。
合理设置消息保留策略,避免过期消息占用磁盘导致性能下降。
监控、限流与应急策略
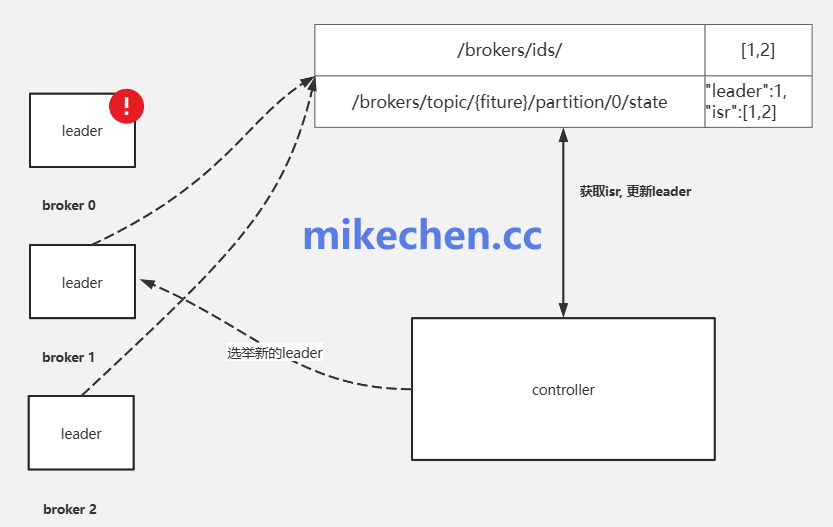
建立完善的监控与应急机制,可在问题扩散前采取措施并快速恢复。
完善监控指标:如Produce/Fetch速率、Consumer Lag、Broker磁盘使用。
网络IO、GC与请求队列长度,结合告警阈值及时通知。
实施动态限流与降级:当检测到堆积或下游压力增大时,临时限制生产速率或降级非关键业务流量。
应急迁移与重平衡:在分区热点或Broker故障时,执行分区重分布、迁移热点分区或临时增加消费者以缓解压力。
定期演练恢复流程,确保在堆积严重时能迅速定位瓶颈并执行回滚或扩容策略。