
分布式是大型架构的核心,下面我重点详解HDFS分布式存储@mikechen
HDFS
HDFS,全称 Hadoop 分布式文件系统 (Hadoop Distributed File System)。
是 Apache Hadoop 项目的核心组件之一,专为处理超大规模数据集而设计。
它不是一个通用的文件系统,而是针对大数据应用进行了高度优化。
支持大文件的高效存储与读取;
提供容错与自动恢复能力;
运行在廉价服务器集群上;
适合一次写入、多次读取的场景。
HDFS 架构
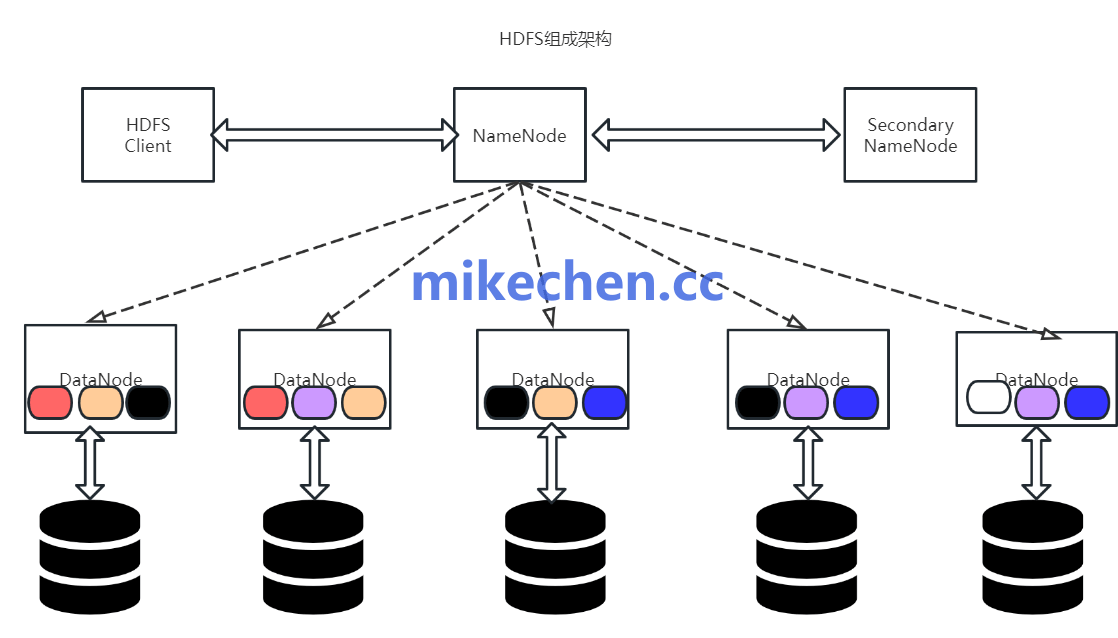
HDFS 采用主从式分布式架构,主要组件包括 NameNode、DataNode、Secondary/Checkpoint Node 等。
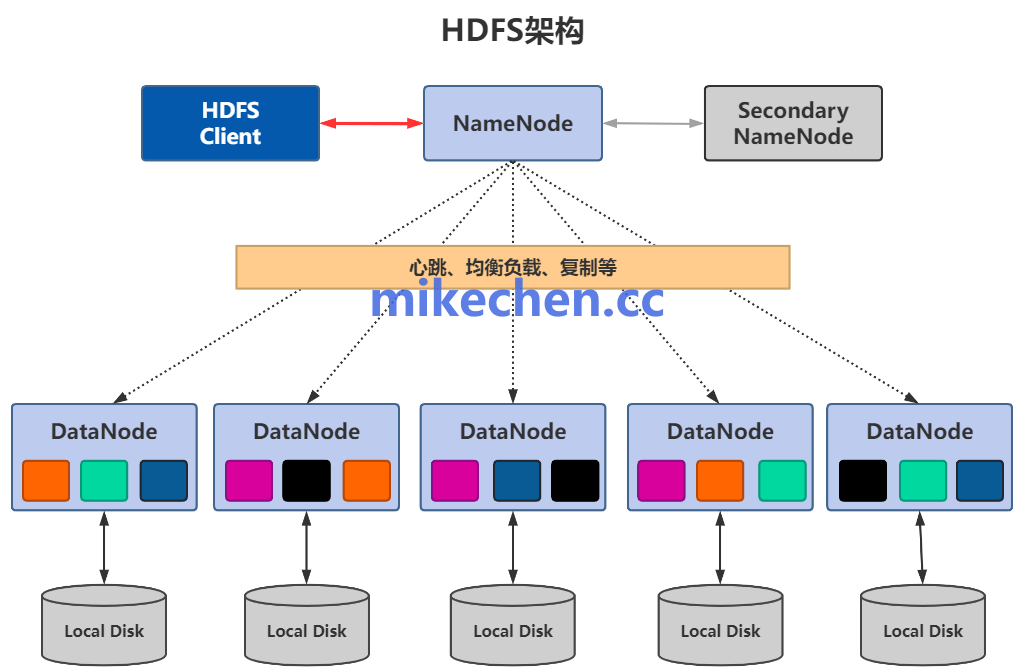
NameNode(主节点)
负责文件系统的元数据管理,包括目录树、文件到数据块(block)的映射、以及各数据块的副本位置等。
NameNode 不存储任何实际数据,只存储元数据。
为了防止单点故障,生产环境中通常会配置 NameNode 的高可用 (HA) 模式,即主 NameNode 和备用 NameNode。
DataNode(数据节点)
负责实际数据块的存储、读写请求的处理以及向 NameNode 定期汇报(heartbeat)和发送块报告(block report)。
HDFS 会将大文件切分成一个个固定大小的数据块(默认 128MB/256MB),并将这些块分散存储在不同的 DataNode 上。
HDFS 应用场景
HDFS 适用于一系列需要大容量、容错和高吞吐处理的场景,典型包括但不限于:

大数据批处理:与 MapReduce、Spark 等计算框架紧密集成,适合离线数据处理、ETL、数据仓库构建等。
日志与事件数据存储:大规模日志收集、存档与分析,如网站访问日志、系统监控日志、传感器数据等。
数据湖(Data Lake):作为存放原始或处理后海量异构数据的底层存储层,支持数据探索与多种处理方式。
媒体与文件存储:存储视频、音频、图像等大文件,尤其是配合批量处理、转码或分发场景。