
Kafka是大厂必备中间件,下面我详解Kafka性能优化@mikechen
增加并行度(水平扩展消费者实例或分区)
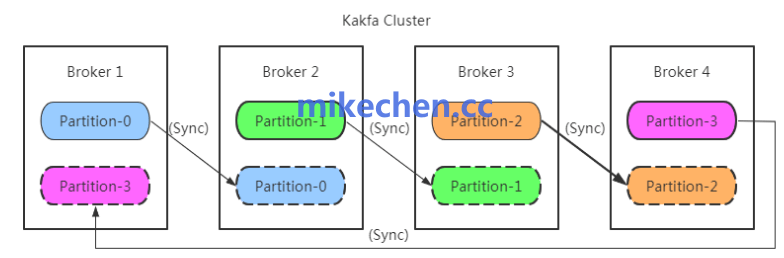
这是最直接的横向扩展手段,Kafka 的消费并行度严格依赖于 Partition 的数量。
对齐数量:确保 Topic 的 Partition 数量大于或等于 Consumer 实例数。
如果 Partition 只有 3 个,即使部署 10 个 Consumer,也只有 3 个能同时工作。
理想配置:通常建议将 Partition 数设置为 Consumer 实例数的整数倍,以实现负载均衡。
注意限制:单台机器的 Consumer 线程数不宜过多,通常受限于 CPU 核心数和内存 IO 性能。
批量拉取与处理(调整 Fetch 和 Poll 参数)

通过减少网络请求次数和 I/O 交互,利用批量操作压榨性能。
fetch.min.bytes:设置消费者拉取请求的最小字节数。
调大此值可以强制消费者等待更多数据入队后再返回,从而减少请求频率。
fetch.max.wait.ms:如果数据量一直达不到 fetch.min.bytes,消费者最长等待多久。
建议配合设置,避免在高并发低流量时产生过高延迟。
max.poll.records:单次 poll() 调用返回的最大消息条数。
在 CPU 处理能力允许的情况下,调大此值可显著提升单次循环的处理效率。
引入多线程并发处理(Consumer 线程池模型)

默认情况下,poll() 和逻辑处理是在同一个循环中同步进行的。
如果业务逻辑(如数据库写入、外部接口调用)耗时较长,会阻塞后续拉取。
线程池架构:采用“1个拉取线程 + N个处理线程”的模型。
拉取线程只负责从 Kafka 获取数据并丢入内存队列,由线程池异步执行业务逻辑。
优化逻辑:批量处理
Kafka 默认是“逐条处理”,这是性能杀手。
ConsumerRecords<String, String> records = consumer.poll(1000);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords =
records.records(partition);
// 批量处理
processBatch(partitionRecords);
}
正确做法:批处理。