
Kafka是大型架构的核心,下面我详解Kafka消息堆积@mikechen
消费端优化
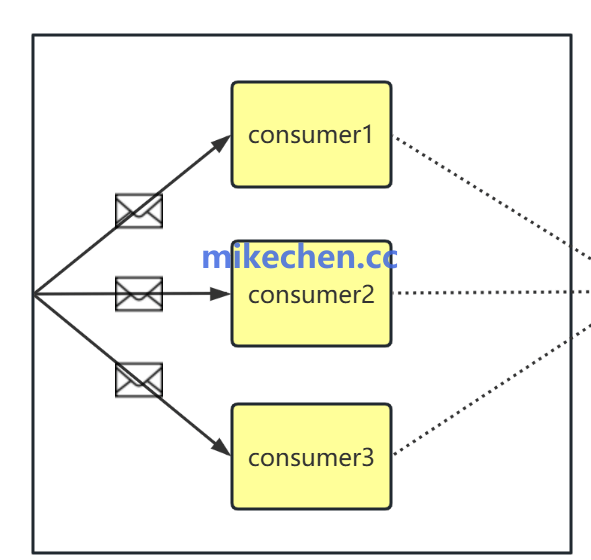
1. 增加Consumer数量(并行消费)
原理:Kafka 每个分区只能被一个 Consumer 实例消费。
优化策略:
增加消费组内消费者数量,提升并行消费速度;
保证分区数 ≥ 消费者数量,否则增加消费者无效。
2. 提高消费逻辑效率
减少单条消息处理耗时(IO、数据库写入、外部接口调用等);
采用批量消费、异步处理、线程池并行消费;
使用 异步ACK 或 批量提交offset。
3. 优化消费端代码性能
避免重试逻辑阻塞线程;
使用内存缓存或队列(如Disruptor、LinkedBlockingQueue)解耦消费与处理。
扩展Kafka集群能力
1. 增加分区数(Partition数)
分区越多,吞吐量越高,可支持更多消费者并行消费;
注意:分区过多会带来元数据负担、rebalance耗时增加。
2. 增加Broker节点
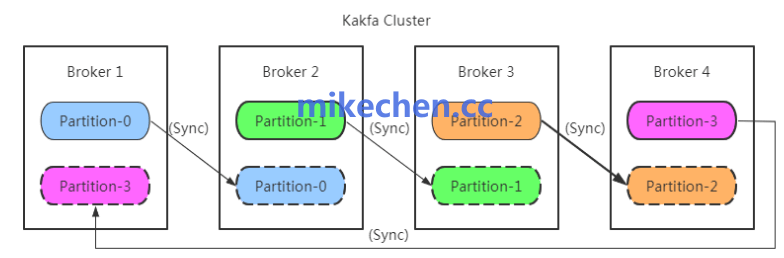
分摊写入压力与网络IO,提高总体并发性能;
适用于单机磁盘、CPU、网络瓶颈的情况。
3. 优化Broker参数配置
num.replica.fetchers:增加副本拉取线程数;
replica.fetch.max.bytes:提高副本同步批次大小;
log.flush.interval.messages、log.flush.interval.ms:减少磁盘写频率。
优化生产端写入(Producer端优化)
1. 增大批量发送
批量发送提升网络利用率,减少请求次数;
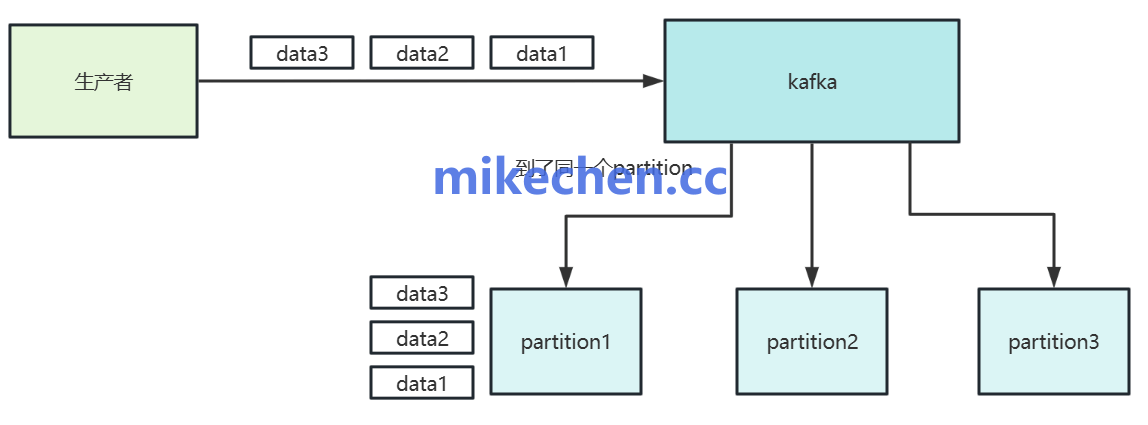
示例:
batch.size=65536
linger.ms=5
2. 调整压缩算法
开启压缩(compression.type=gzip 或 lz4)可显著降低带宽与磁盘压力;
建议使用 lz4 或 zstd(压缩率高、解压快)。
3. 异步发送与ACK机制优化
生产者可使用 acks=1 替代 acks=all 提升速度(但可靠性略降);
或通过 max.in.flight.requests.per.connection 控制并发请求数。
架构层面异步削峰(系统设计优化)
1. 增加缓冲层(如Redis、内存队列)
当Kafka消费速度不够时,临时将数据写入Redis或内存队列,平滑突发流量;
避免生产者直接压垮Kafka。
2. 分层消费架构
快速消费层:仅负责快速拉取Kafka数据;
业务处理层:异步消费处理,防止业务逻辑阻塞Kafka线程。
3. 使用流处理框架(Flink / Spark Streaming)
支持并行度控制与动态扩容,可自动应对堆积场景;
在消费侧实现流量控制、backpressure、checkpoint机制。