
百万并发场景
微服务拆分的核心目标是,将复杂系统按业务功能垂直切分成若干独立可部署的服务。

每个服务:
独立开发、部署、扩展;
职责单一,接口清晰;
通过轻量通信(如 HTTP、gRPC、MQ)进行交互。
这样做可以消除单体系统的性能瓶颈,使每个服务独立扩展,支撑更高并发。
确保每个服务拥有明确的业务边界、与数据边界。
数据域边界,尽量让服务拥有自己的数据库或数据存储,避免跨服务直接访问同一数据库的写冲突与耦合。
高频路径优先拆分,将高并发、对响应时间敏感的核心路径。
比如:下单、支付、库存变更。。。等等独立成服务,便于独立扩容与优化。
数据拆分
当单库、或单表、的数据量,达到数千万甚至上亿时:
查询性能急剧下降;
读写锁冲突严重;
磁盘 I/O 成为瓶颈。
此时需要进行“数据层拆分”。

垂直分库
将一个大库按业务模块拆成多个数据库:
-
user_db(用户库);
-
order_db(订单库);
-
product_db(商品库);
每个数据库独立部署,分担 I/O 压力。
水平分表
按数据量拆分表结构。
将单张大表按规则拆成多张表,例如:
按用户ID取模:order_0, order_1, order_2 …
按时间分表:order_2025_10, order_2025_11 …
服务限流
限流的目标是:让系统在高并发流量下保持稳定,而不是被压垮。

在高并发场景下,系统面临以下典型问题:
系统雪崩(请求堆积导致服务不可用);
线程池耗尽(大量阻塞请求);
数据库崩溃(并发写入过多);
全链路宕机(单点故障扩散);
因此,限流是系统自我保护机制,与熔断、降级、隔离一起构成“高可用四件套”。
服务熔断
当某个服务出现异常或响应过慢时,调用方不能无限等待,否则容易造成雪崩效应。
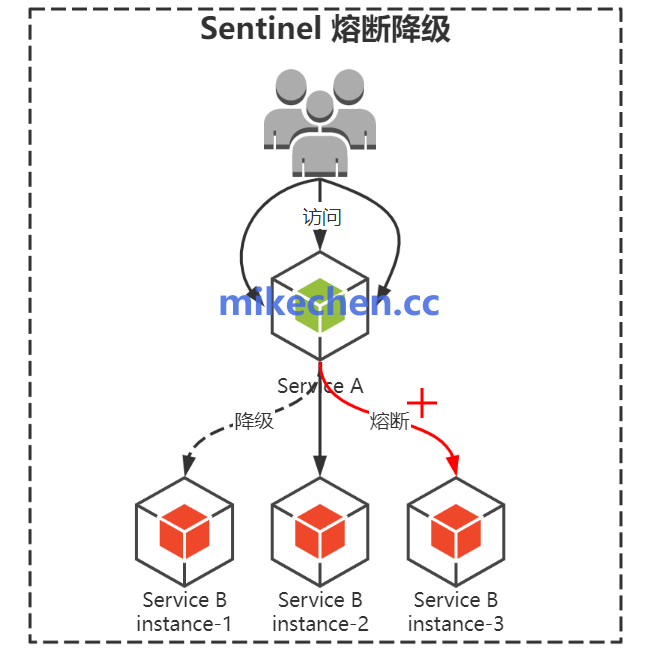
当检测到失败率或超时率达到阈值时,自动断开请求。
比如:失败率阈值(例如 50%)且最小请求数(例如 20 请求/窗口)或延迟阈值。
直接返回预设结果,待目标服务恢复后再自动关闭熔断。
常见实现
Hystrix:Netflix 提供的早期经典实现;
Resilience4j:轻量级新方案;
Sentinel:阿里开源的分布式流控与熔断系统。
服务降级
即使部分服务不可用,系统也不应完全崩溃,而是“有损可用”。
当系统检测到服务超时、熔断、或资源紧张时,自动启用降级逻辑:
-
返回默认数据;
-
屏蔽非核心功能;
-
延迟执行或排队。
比如:
商品详情降级:若评论系统超时,只展示商品信息;
支付服务降级:支付通道异常时,暂存订单稍后处理;
推荐服务降级:推荐系统不可用时返回热门商品。