
分布式是大型架构核心,下面我详解分布式缓存雪崩@mikechen
什么是缓存雪崩
缓存雪崩是分布式系统中最常见、最具破坏性的缓存故障之一。
指的是——在同一时间,大量缓存数据同时失效或缓存系统不可用。
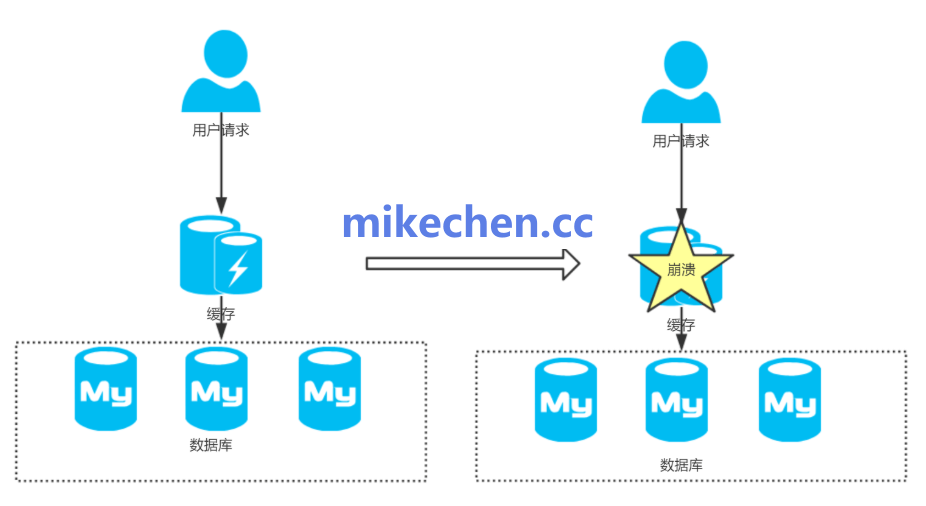
导致海量请求瞬间涌入数据库或下游系统,造成系统整体性能骤降甚至崩溃。
通俗地说:原本该由缓存挡住的流量,突然全部打到了数据库。
就像雪崩一样,一层带一层,最后把系统压垮。
为什么会发生缓存雪崩
大量缓存同时过期,比如:某些高频访问的 Key(如热门榜单、爆款商品)过期。
由于访问集中、重建延迟短,瞬间造成大量请求打穿缓存层。
在瞬间的大并发访问下,所有请求直击数据库,引起后端负载暴涨。
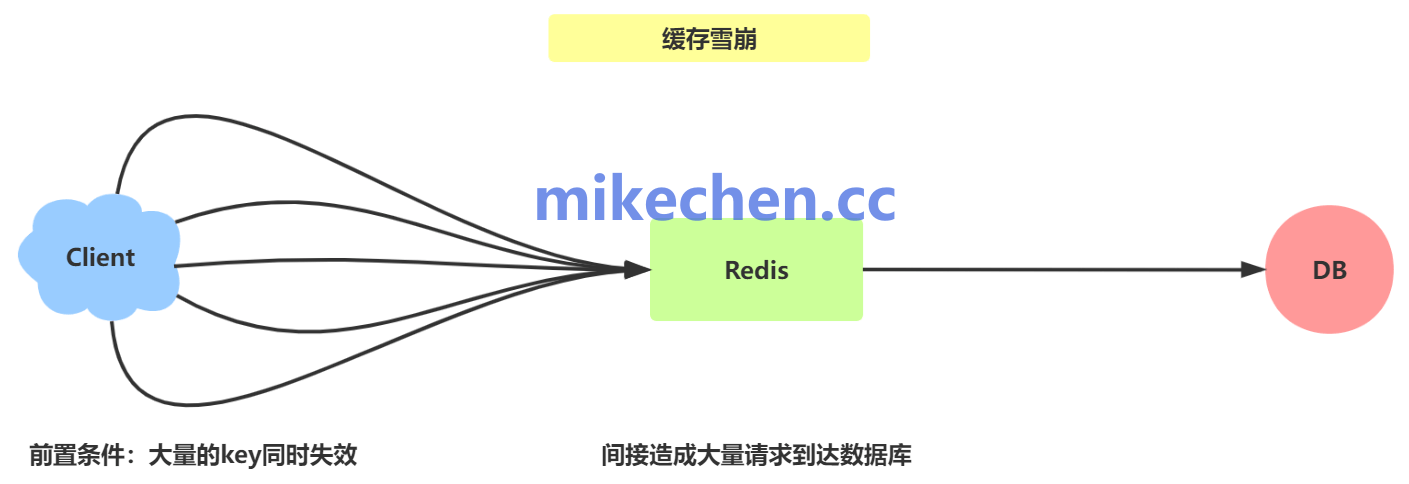
举例:电商首页热点商品缓存设为 1 小时整点刷新,结果 10:00 同时失效,用户访问瞬间全部打到 MySQL。
缓存雪崩解决方案
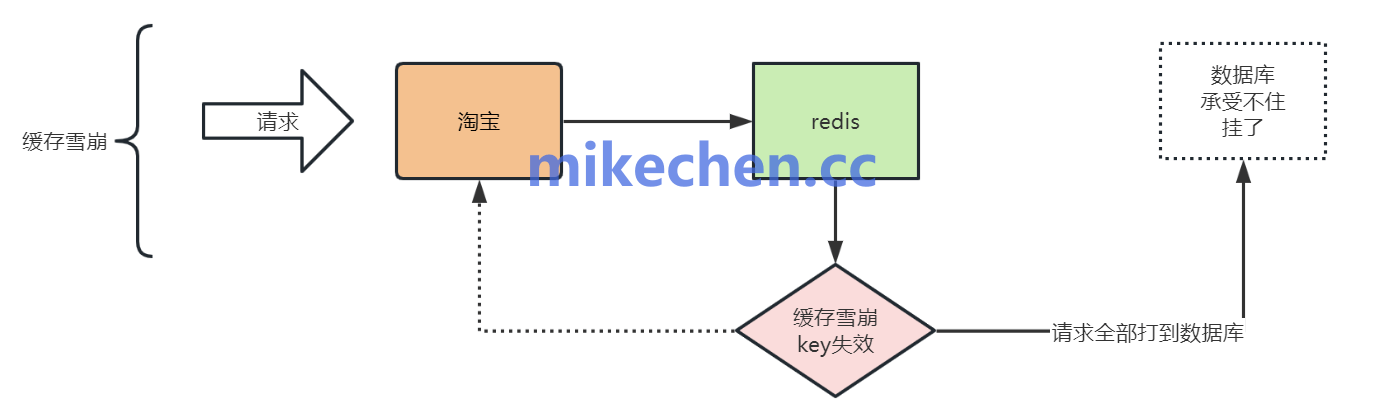
1.过期时间错峰(TTL 随机化)
原理:为缓存项设置随机化的过期时间,使缓存失效时间分散,避免集中失效。
优点:实现简单,能显著降低同时失效的概率。
注意:随机范围应基于业务访问特性合理配置,避免过大导致缓存不一致窗口。
2.互斥锁或请求排队(防击穿)
原理:当发现缓存未命中时,通过分布式锁、单机互斥或请求合并(例如“请求合并器”)只允许一个请求回源加载数据,其余请求等待或返回缓存旧数据。
优点:避免大量并发请求同时回源,保护后端稳定。
注意:锁的超时和异常处理需谨慎,防止死锁或长时间阻塞。
3.预热与主动刷新(无损更新)
原理:对于热点数据,预先加载到缓存并在到期前主动刷新(后台异步更新),或采用“先更新缓存再更新源”的策略保持缓存持续有效。
优点:降低缓存失效概率,保证热点数据连续命中。
注意:需设计好刷新频率与并发刷新策略,防止刷新时的集中回源。
4.限流、降级与熔断(保护后端)
原理:在高并发或后端压力上升时,通过限流、熔断或降级策略限制请求到后端,返回降级结果(如静态页面、降级数据或错误提示),或缓慢回退以保留核心功能。
优点:保证系统在异常流量下的可用性和稳定性,避免完全崩溃。
注意:降级策略应兼顾用户体验与关键业务保障,需监控与可观测性支持决策。