
Kafka是大型架构核心,下面我详解Kafka百万并发技术@mikechen
顺序写入
Kafka 采用顺序追加写入(append-only log)存储消息,充分利用磁盘顺序写入的高效性,显著降低随机 I/O 开销。
Kafka 把消息按 Partition 组织成日志文件,只在文件尾部追加(append-only)。
消费者按 offset 顺序读取,避免随机读写。
为什么快?因为:机械硬盘随机读写是瓶颈(磁头寻道耗时)。
顺序追加是机械硬盘最优模式,吞吐可达数百 MB/s。
Partition 模型天然支持并行:多 Partition 可分布到多 Broker、多磁盘并发处理。
多 Partition ,进一步放大到集群级百万并发。
分区化与并行处理
Kafka 将主题(topic),划分为多个分区(partition)。
每个分区,为一个有序的消息序列并由单一副本(leader)负责读写。
通过增加分区数与复制副本,Kafka 可将负载在集群内水平分散,提升并发处理能力与吞吐量。
同时,分区的独立性使得消费者组可并行消费不同分区,从而线性扩展消费能力。
批量传输与压缩

Producer 批量攒消息(linger.ms + batch.size)。
Broker 批量落盘、Consumer 批量拉取,支持消息压缩(snappy/lz4)。
为什么快:
单条消息网络/磁盘开销高,批量处理把 N 条消息合并成 1 个请求/写操作,摊薄开销。
压缩后数据量减半,网络带宽利用率翻倍;Producer 端异步批量发送,减少连接数。
实战价值:
默认配置下,Producer 每批 32KB、linger 5ms,就能轻松把单机 TPS 从万级提到百万级。
Consumer 拉大批量(fetch.max.bytes),配合多线程并行消费 Partition,进一步放大并发能力
页缓存
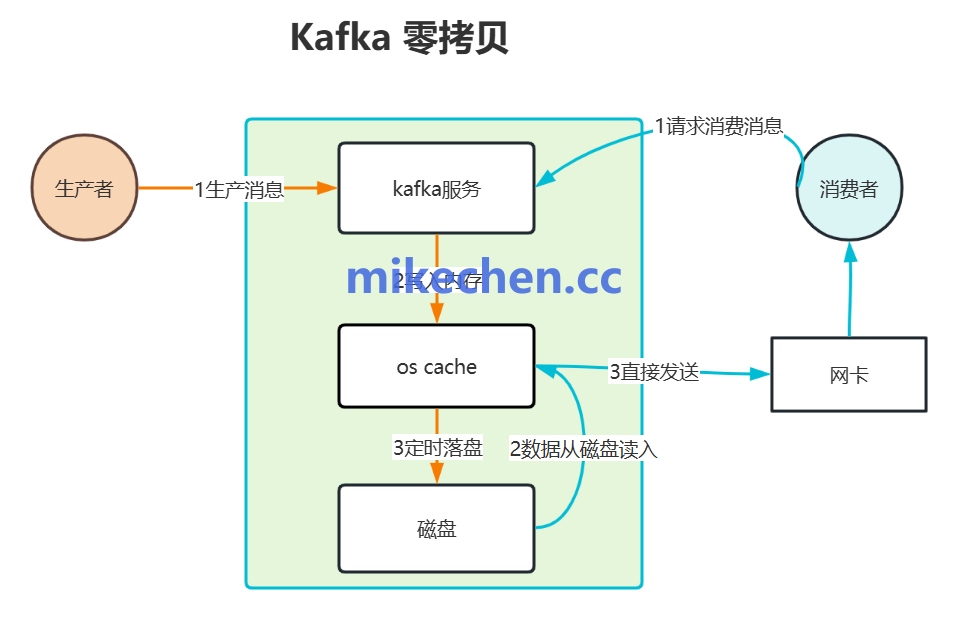
Kafka 并没有在应用层自己管理缓存(即不使用大量的 JVM Heap),而是完全交给了操作系统的 PageCache。
原理:Kafka 通过 MMap (Memory Mapped Files) 将文件映射到虚拟内存。当写入数据时,其实是写到了操作系统的内存缓冲区。
架构优势:
避开 GC:因为数据在内核内存中,不会触发 Java 频繁的垃圾回收,保证了系统的稳定性。
热数据快速消费:生产者刚写的消息还没落盘,消费者就直接从 PageCache 里读走了,速度极快。