

在大数据量高并发的系统,经常会涉及到缓存穿透的问题,这也是阿里等大厂经常会考察的一个问题。
如果处理不好会严重会造成系统宕机,所以需要认真考虑如何来应对,本篇详解4大方案@mikechen
缓存穿透
Redis缓存穿透是指在访问缓存时,由于请求的数据本身不存在,直接穿透到数据库。
比如:最常见的就是“黑客攻击”,通常发生在一些非法请求上。
或者,比如:恶意用户利用不存在的key频繁请求数据,导致缓存不命中,进而请求到数据库。
如下图所示:

攻击者故意发送大量不存在的数据请求,绕过缓存,直接对数据库造成压力。
如果发生“缓存穿透”,如果请求量很大的情况下,比如:上万次/秒的请求,会导致大量请求直接落到数据库。
找个时候,增加数据库的负载,在高并发场景下可能引发数据库崩溃,导致系统不可用的“线上重大事故”。
所以,针对这样的情况,需要技术手段来解决。
比如,会涉及到如下方案:
方案一:缓存空对象
当数据库查不到某个数据时,可以将空结果也缓存起来,设置一个较短的过期时间(如:几分钟),防止缓存了大量空值。
这种方法可以避免,重复查询同一条不存在的数据,但是,也有一个非常的缺点:
就是会极大的增加缓存空间的占用,尤其在空值较多的情况下。
方案二:限流
对频繁请求的接口,设置限流规则,当请求超过一定阈值时,阻止请求继续访问数据库。
采用这种放哪,有可能会影响正常用户的请求,限流策略设置不合理,可能导致用户体验变差。
方案三:布隆过滤器
在缓存、和数据库查询前,先通过布隆过滤器快速判断请求的数据是否存在。
布隆过滤器,可以用较小的内存高效地记录已有的数据,如果布隆过滤器认为数据不存在,则直接返回,不再查询缓存和数据库。
如下图所示:
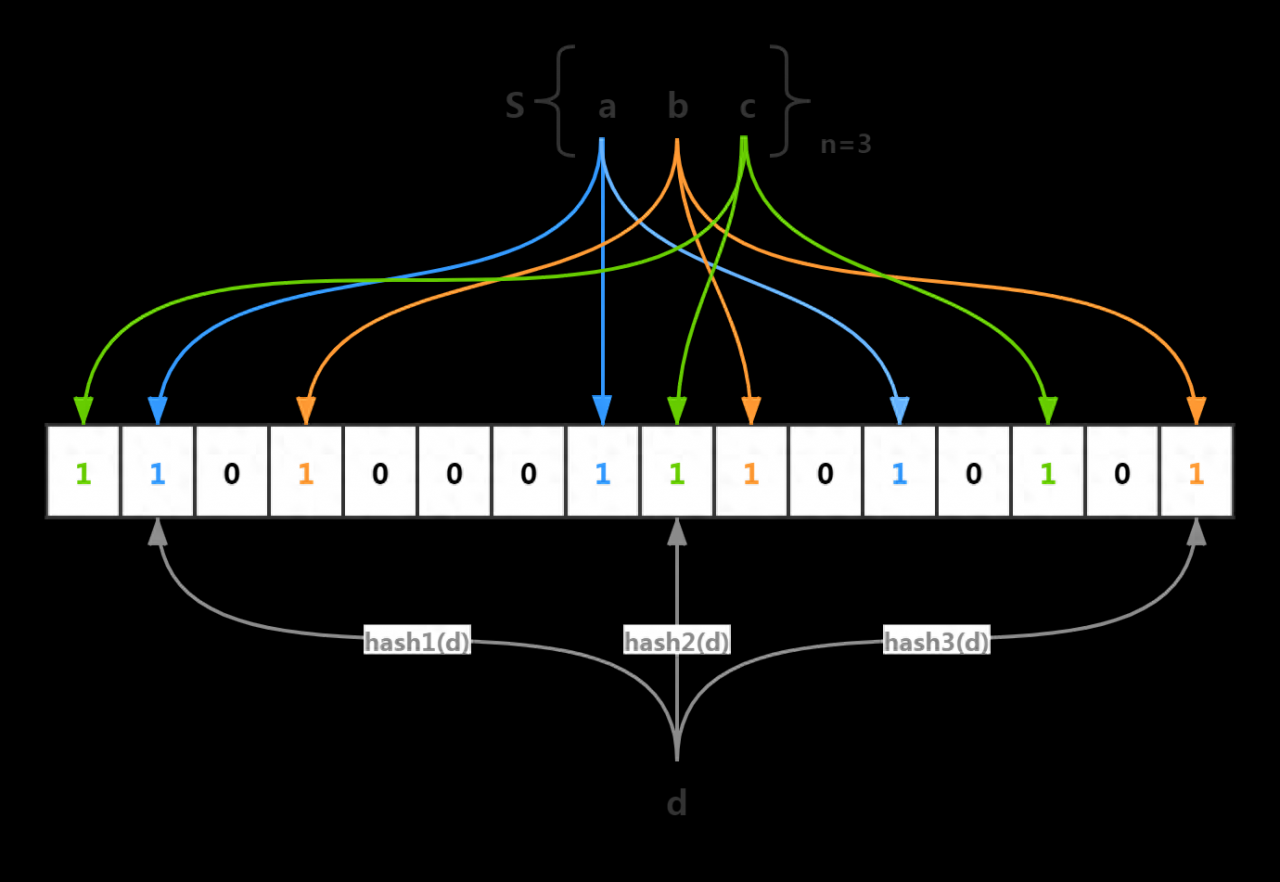
这种方案的成本相对以上的方案,成本更小,但也存在:“误判率”。
一般实际应用中,会将多种方法组合使用,以获得更好的效果。